

{kind=link}
過去在文本抽取中要抽取實體(Named Entity Recognition;NER)需要進行大量標注,本次要透過單一模型抽取不同領域的文本內容,而且尚未經過fine tune就能取得不錯的表現.
另外過往在抽取實體的過程比較難用簡易的自然句表示想要抽取的事項,再來是抽取的事項無法看出關聯性,但透過本次實驗可以看出來,除了抽取出相關實體外還可以抽出他們的關係,這樣就可以做更多的應用.
一、痛點
- 模型需要進行大量標注
- 模型具有領域性,無法跨領域應用
- 無法用自然語言去表述抽取項(E.g : 住院幾天?)
二、解決方案
- 通過模型可以進行中文跨領域抽取,也可以進行領域性fine tune
三、展示-法律相關
- 問句
- 法院
- 書記官
- 被告->吐氣酒精濃度
- 刑事庭->法官
- 審判長
- 檢察官
- 透過以上問句,找出法院判決主文,並且提取相關內容,結構化展示
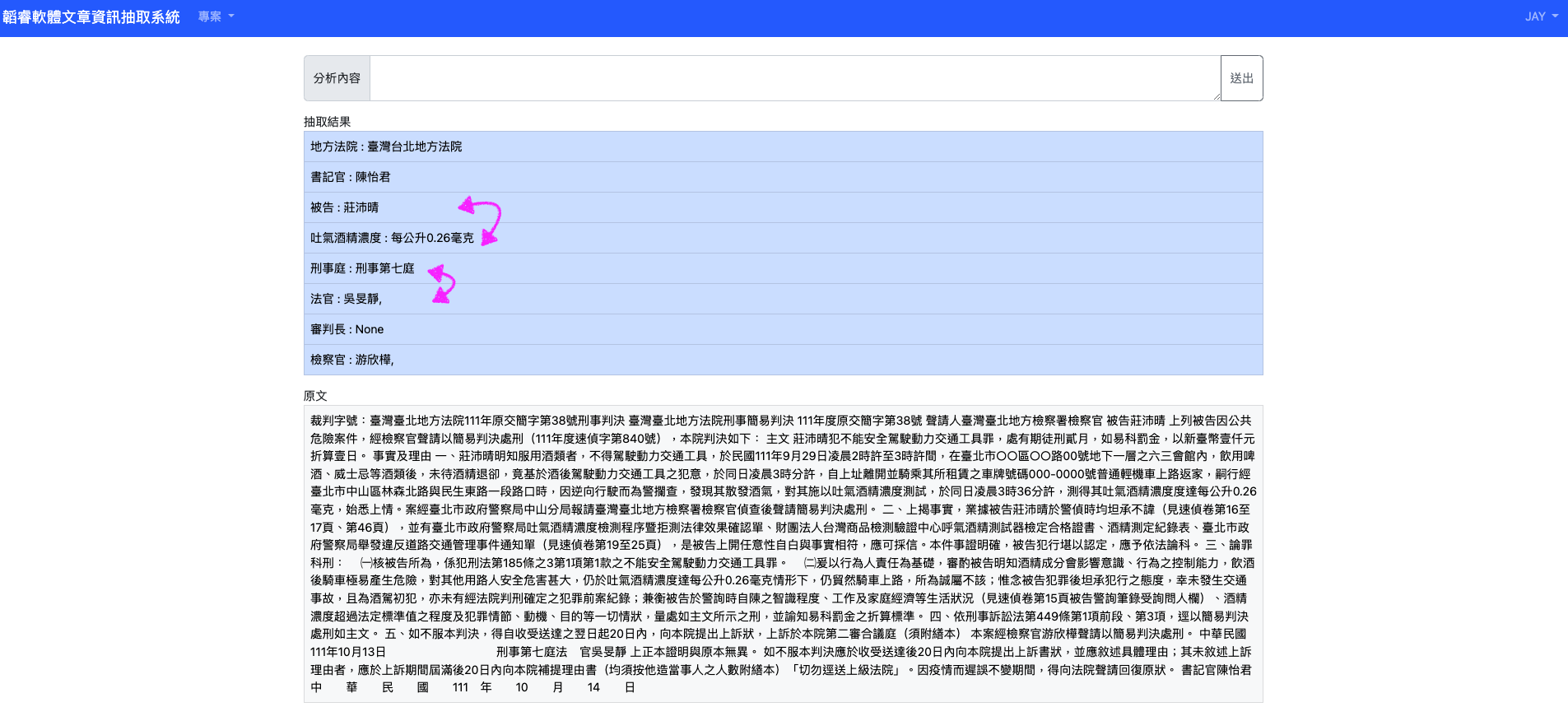
- 範例一 – 臺灣臺北地方法院 111 年度原交簡字第 38 號刑事判決
- 由於判決文過長,所以這邊僅節錄抽取出跟被告有關的酒精濃度與刑事法庭有關的庭號
- …對其施以吐氣酒精濃度測試,於同日凌晨3時36分許,測得其吐氣所含酒精濃度達每公升0.26毫克,始悉上情。案經臺北市政府警察局中山分局報請臺灣臺北地方檢察署檢察官偵查後聲請簡易判決處刑。…
- …刑事第七庭 法 官 吳旻靜 ….
四、展示-醫療相關
- 問句
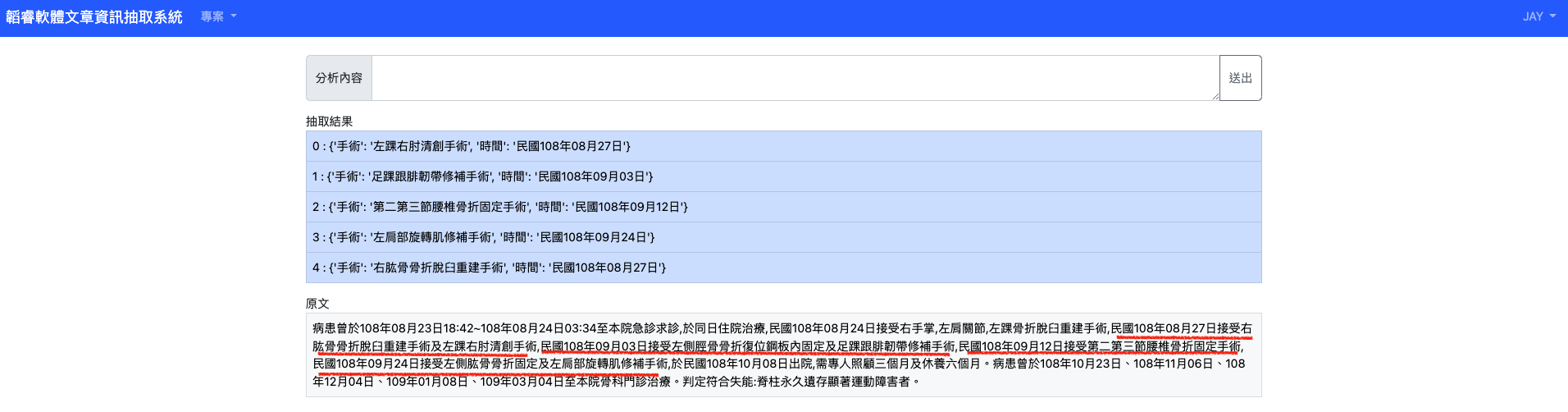
- 手術->時間
- 住院天數
- 放射線次數
- 放射線劑量
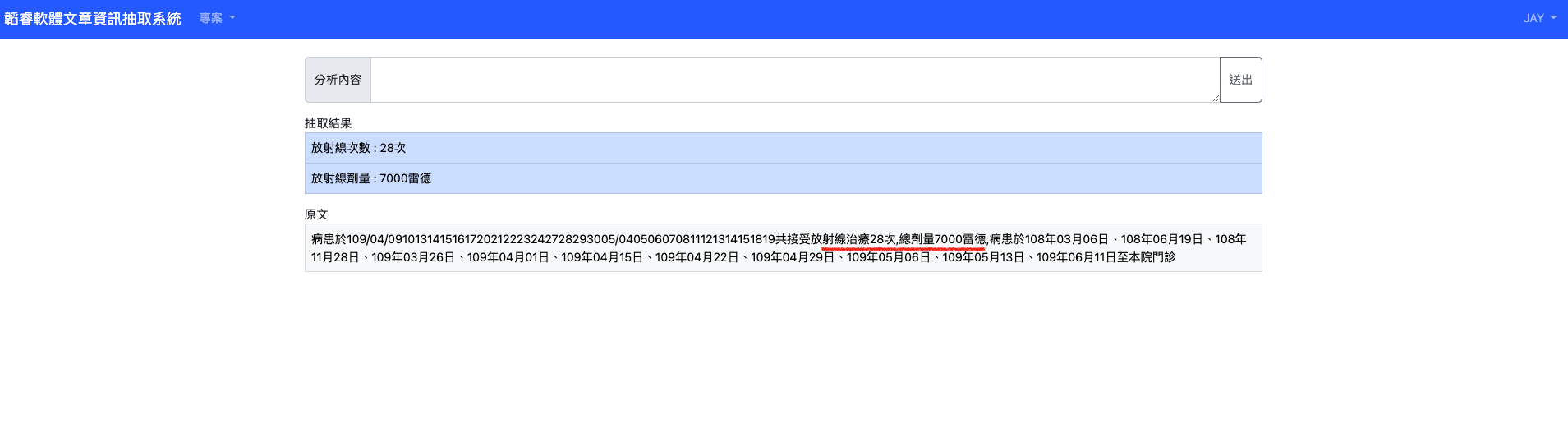
- 範例一 – 含有放射線
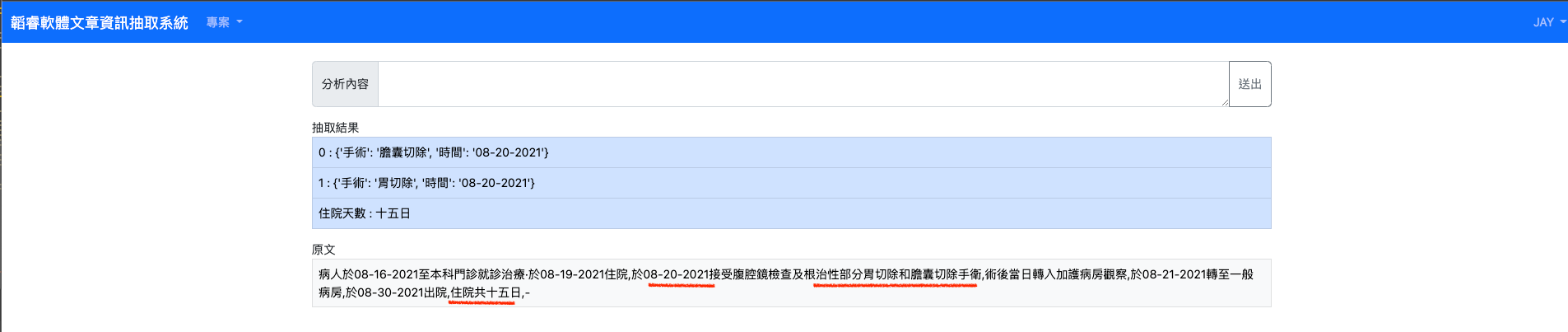
- 範例二 – 多手術與有住院日期
- 範例三 – 多手術
五、結論
通過上述展示,在同一個模型下做跨領域的應用抽取,且尚未進行微調,可以看得到實際得出的結果是含有關聯性在,唯一不足的是T編在使用的時候還是會有抓取不到的部分,或是抓取多個,相信微調後效果更高.
但透過此方法可以進行多樣態的抽取(同時可以詢問多種問題,以及問題可以回覆多個答案),且可以比較以接近人類口吻的方式來進行詢問(E.g 住院天數),並看出關係.
六、備註
本次測試樣本,法律資訊來自於司法院 判決書查詢系統,屬於公開資料,所以並未進行隱碼,是採用隨機抽取方式進行;醫療資料為虛構資料,如有雷同純屬巧合.
![]()