

{kind=link}
在去年T編有介紹了Python結合Pandas的基礎應用,本次要介紹一個用於資料清洗或是重複資料篩選的方法,應該會是許多財務會計或是在進行一些統計分析的人會使用到.
零、樣本準備
有一份Excel內容類似這樣
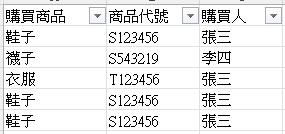
壹、把它變成你期望的樣子
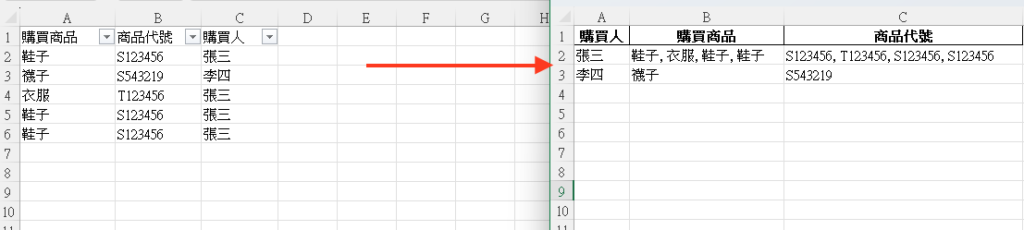
希望可以產出一份Excel變成,以購買人為主,知道購買了哪些產品,類似以下

貳、該怎麼做呢?
```python
import pandas as pd #載入pandas
#設定要使用的資料
df = pd.read_excel("測試資料.xlsx")
#主要的程式
df_merged = df.groupby('購買人').agg({
'購買商品': lambda x: ', '.join(x),
'商品代號': lambda x: ', '.join(x),
}).reset_index()
#存檔
df_merged.to_excel("output.xlsx", index=False)
```
參、觀看結果
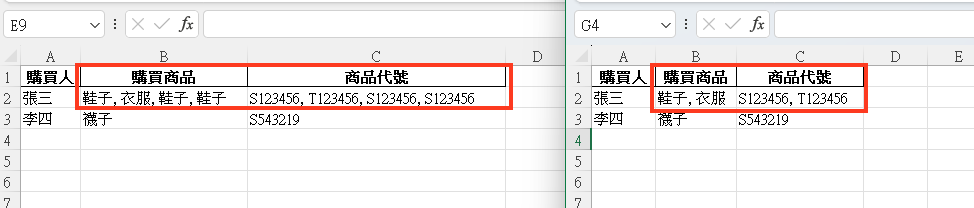
肆、只能這麼單嗎?換個方式!
我這次希望達成是購買商品與商品代號,如果有重複出現,僅出現一次即可,我只需要知道購買人買過該商品,該怎麼做?
```python
import pandas as pd #載入pandas
#設定要使用的資料
df = pd.read_excel("測試資料.xlsx")
#主要的程式
df_merged = df.groupby('購買人').agg({
'購買商品': lambda x: ', '.join(set(x)),
'商品代號': lambda x: ', '.join(set(x)),
}).reset_index()
#存檔
df_merged.to_excel("output.xlsx", index=False)
```
有發現到什麼不同嗎?就是在join時候採用set(x)這樣就會過濾掉重複購買的商品與代號
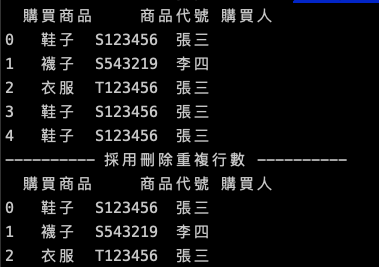
伍、還有什麼方法可以用呢?
假設今天我是要以每個列來看有重複先行濾除,該怎麼做?
```python
# 主要是這行
df_filtered = df.drop_duplicates(subset=['購買人', '購買商品'])
df_merged = df_filtered.groupby('購買人').agg({
'購買商品': lambda x: ', '.join(x),
'商品代號': lambda x: ', '.join(x),
}).reset_index()
df_merged.to_excel("output3.xlsx", index=False)
```
可以看到作法很簡單,就是先透過drop_duplicates進行過濾假設購買人與購買商品欄位一樣,有多筆就只會留下一筆資料
陸、小技巧
之前使用上會遇到一些錯誤,通常都是因為Excel撈出來Pands會判別型態不是文字型態,所以無法使用,所以這邊就可做幾個設定
```python
#強制將此欄位轉為文字型態
df['購買人'] = df['購買人'].astype(str)
#將內容也轉文字型態避免錯誤
'購買商品': lambda x: ', '.join(set(x.astype(str)))
```柒、最後T編說
以上就是本期的分享,當然這些操作用其他的語言甚至Excel都有機會辦到,不過就是看您熟悉哪個語言.
至於為什麼要這樣做呢?很簡單其實透過上述幾種方式,只要再搭配圖形化統計,很快就可以產生漂亮的圖表了,這T編有機會再跟各位分享.
![]()