

{kind=link}
通常在撰寫一些報告做研究時,會參考一些外部資料,或是在做自然語言處理時,總需要把一些檔案格式進行轉換成純文字進行使用,但PDF又分為可以編輯與不可以編輯的格式,所以時常在解析的時候發生很多問題,透過此工具可以快速分離PDF內文、圖片、表格,另外對於無法解析的內容也可以透過OCR進行解析.
一、痛點
前幾期有介紹過透過AI OCR進行進口報單等資料辨識,本期要說的是其企業內部或是個人會有一些PDF的文件,當要對PDF文件行操作時候後,通常都比較難處理,不像是Word可以輕易複製貼上.
故本期將介紹韜睿軟體的DPF解析功能,透過我們的工具可以快速抽離PDF文本、圖片、表格,難以處理的PDF也可以透過OCR的方式進行辨識抽取.
二、解決方案
1.透過本API可以直接進行PDF文字、圖片分離功能
2.透過本API可以直接進行無法拆解之PDF辨識功能
3.進階應用可以進行表格的萃取
三、展示
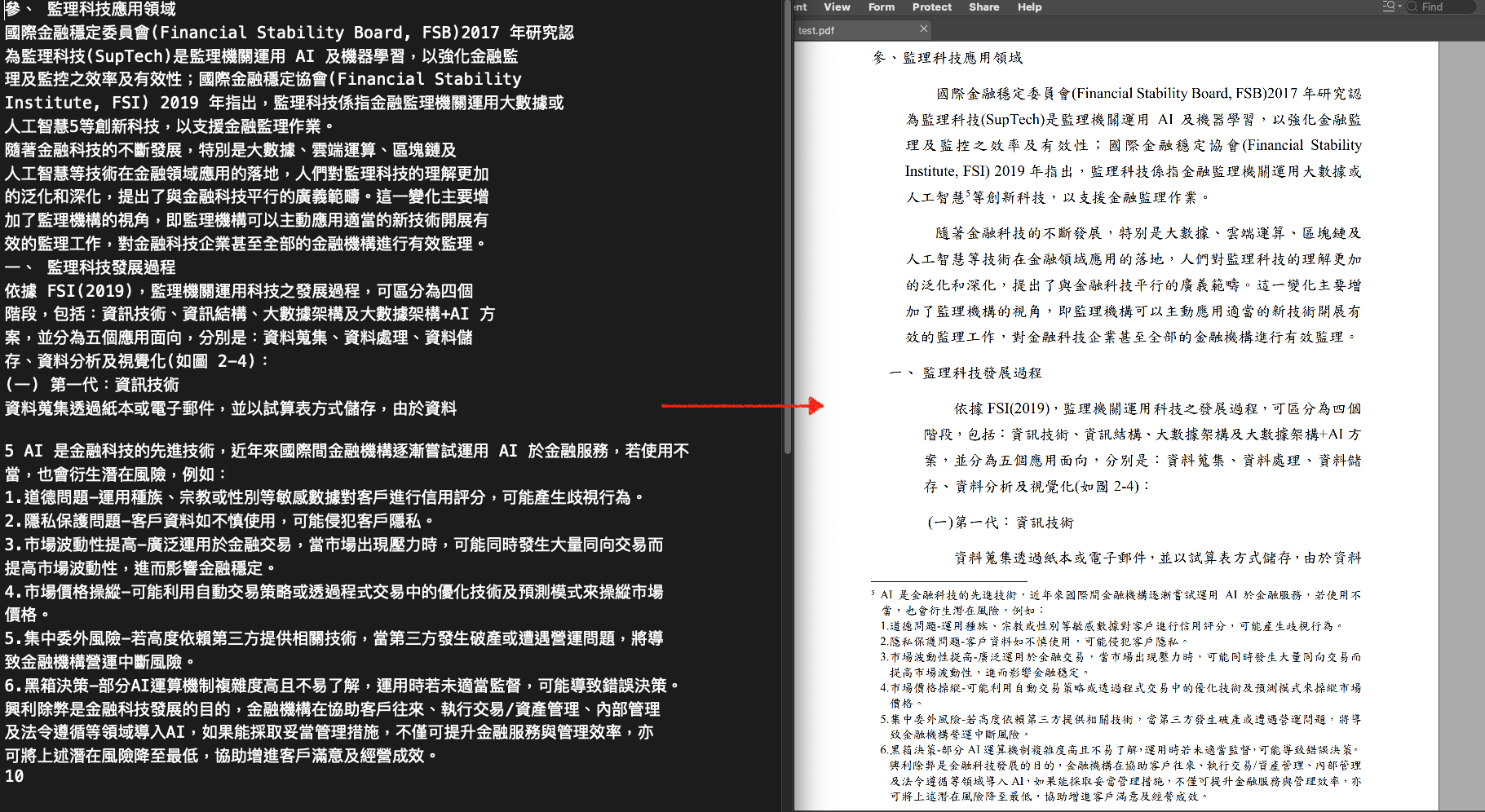
1.原始PDF


2.總萃取出

3.抽取出PDF中的圖片

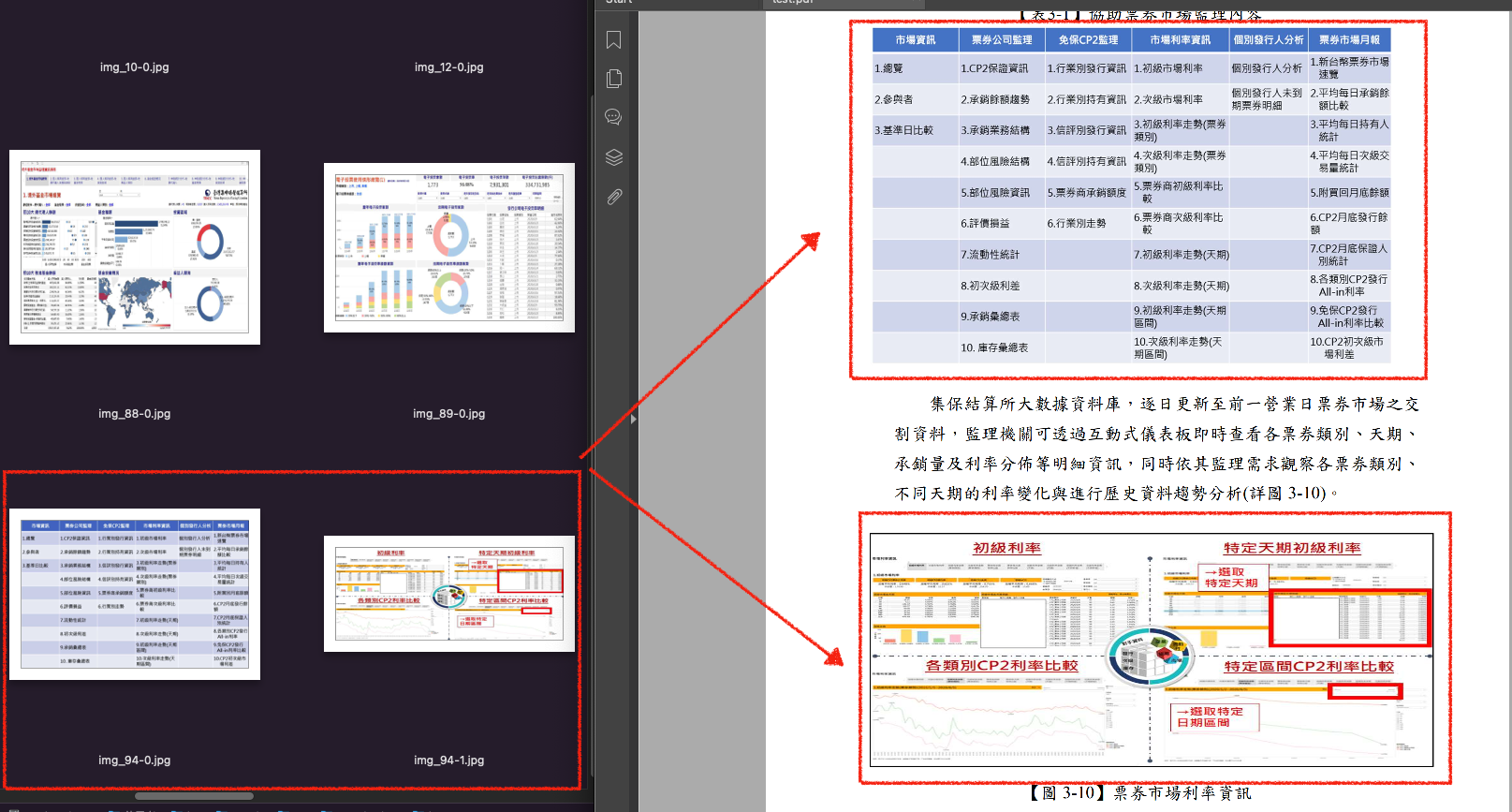
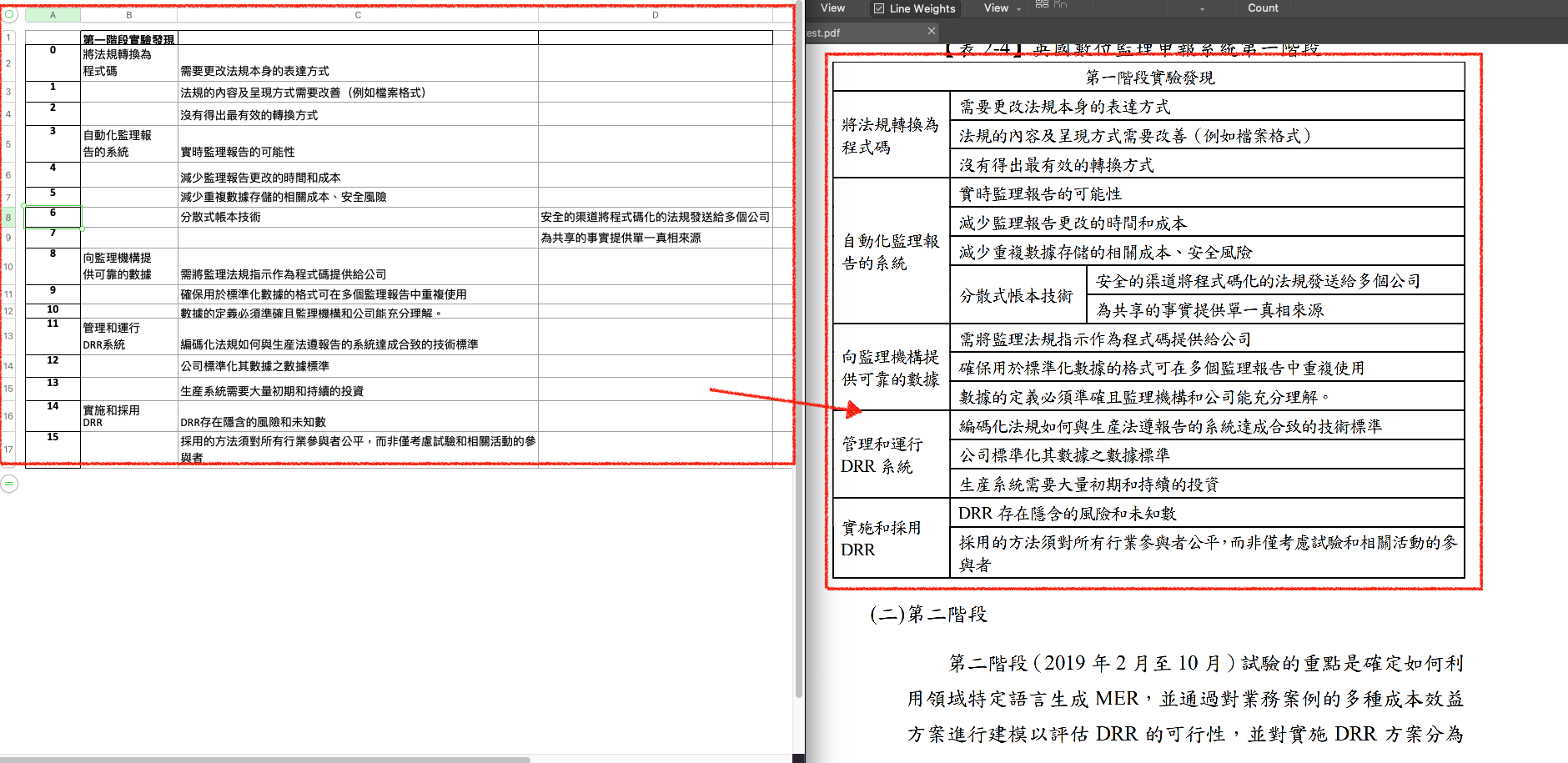
4.抽取出PDF中的表格

5.抽取出PDF中的文字
6.遇到難纏的PDF怎辦?
有的PDF整篇文章是個圖片該如何萃取?透過強大的AI OCR辨識引擎就可以完整辨識出來.

四、總結
透過本API可以快速將PDF分離拆解,讓使用者可以專注在更核心的事物上,透過此方式可以轉換至Word、純文字檔案或是資料庫,近一步進行NLP分析與應用.
就算是無法解析的,也可以搭配AI OCR應用快速輸出文字,而蠻多實務應用是企業有很多合約檔案,都是PDF掃描格式,除了辨識抽取外也可以針對合約進行差異性比對,有機會T編在介紹一些有關NLP的後續應用.
五、宣告
本次案例之PDF皆是網路上公開資訊.
![]()