
AI 與 SaaS 應用需求持續升溫,專注於企業數
![]()

文字辨識與自然語言處理的專家
韜睿軟體入選人工智慧科技基金會(AIF)與台智雲所發佈之「2025 台灣 AI 新創地圖」(Taiwan’s AI Startup Map 2025)名單中,可作為企業選擇數位轉型夥伴之參考.
![]()
讓模型「聽得懂人話,自己決定要做什麼」
透過MCP讓模型不只是生成文字,而是能「理解語意 → 做出決策 → 呼叫工具 → 產生動作」,類似AI代理人(AI agent)。
這一篇,T編想用一個更實際的例子展示這件事怎麼被落地實作。 我們利用 FastMCP 建立了一個簡單的 MCP 服務,並讓 Claude 作為前端的用戶端.
![]()
在現代工作環境中,跨平台查詢資訊降低效率。本文教你如何從零打造 Slack 機器人,並整合韜睿軟體 AI OCR API,自動化票據處理與多系統資訊同步,有效提升團隊協作與工作效率。
![]()
你是否也曾經遇過這樣的狀況?OCR 雖然能幫你把支票轉成文字內容,但轉出來的結果還是得靠人眼一欄一欄去看、去整理,才能填進後續系統裡。這類資料輸入的工作不難,但非常耗時。尤其是文件格式固定、欄位重複性高的情況,其實是最適合交給 AI 模型處理的場景。
韜睿軟體實作了一個微調(fine-tuning)任務:讓語言模型讀懂 AI OCR 後的支票內容,並自動輸出成 JSON 結構,直接可供系統使用。
![]()
相信大家都已經很熟悉LLM (Large Language Model, 大語言模型),不過其實現今的大模型已經可以做到多模態(MutilModel)的應用,也就是LLM不在只是可以看懂文字,甚至可以看懂圖片、描述圖片等等,在這個「看」的領域中除了過往的電腦視覺(Computer Vision;CV),因應大模型開始有了VLM(Vision Language Models, 視覺語言模型 ).
本篇文章說明VLM、Computer Vision、OCR差異
![]()
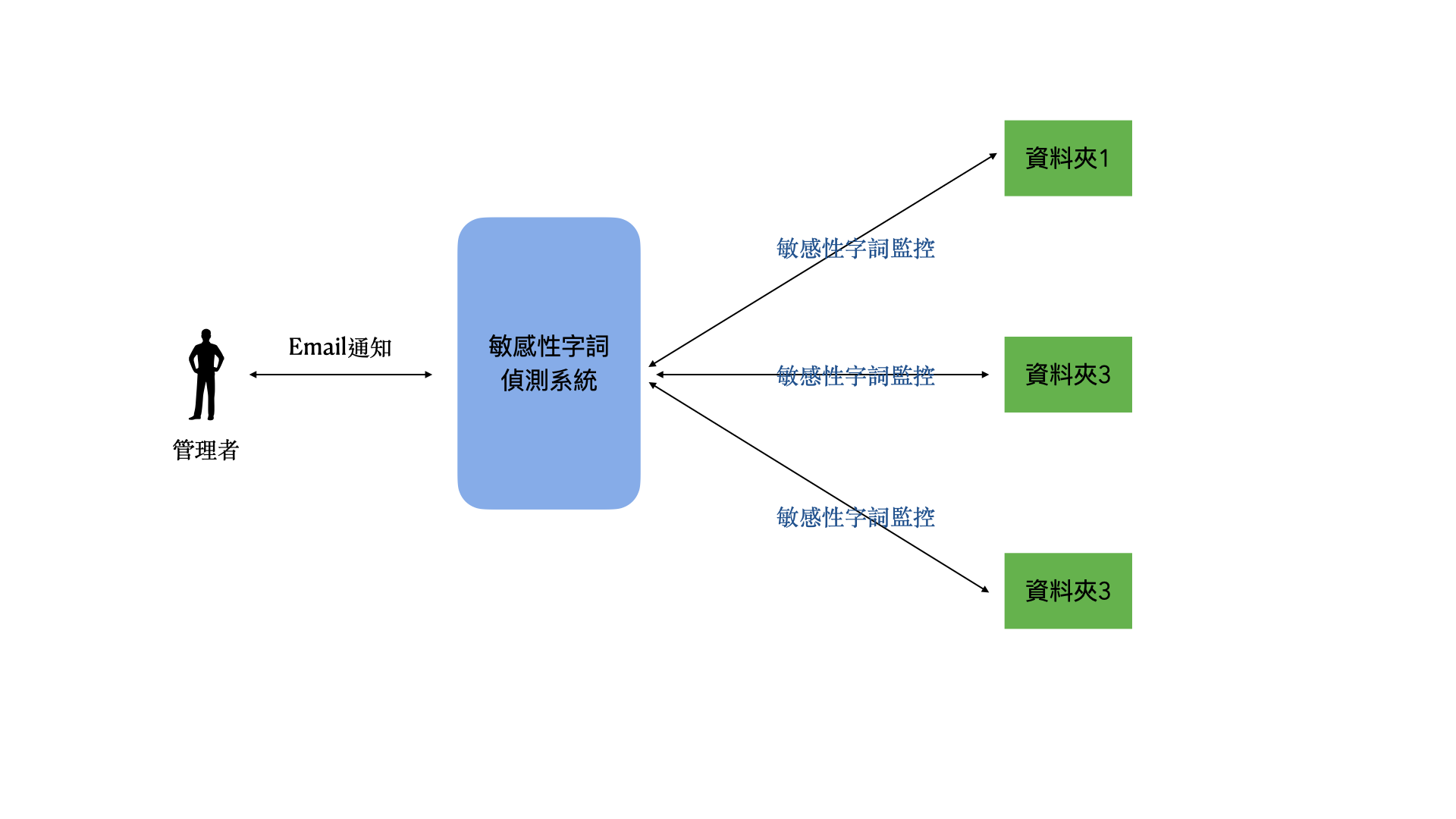
企業內部有許多的作業可以做流程自動化,但牽涉的範圍很廣,韜睿透過模擬人的感官方式,Smart Detector代表人的眼睛,可以幫你處理掉重複的登打作業,而韜睿研發的LLM搭配Smart Detector更可以像是人類的大腦與眼睛的結合,讓各式紙本、圖片可以快速錄入,進行後面的自動化流程.
Smart Detector具備先進LLM技術,也具備輕量化的AI表單抽取技術,讓使用者可以依據場景自行選擇要用的方式,完成企業內文件自動擷取,可進行不同作業如:
自動化: 透過辨識完成,可以抓出關鍵資訊進行分類歸檔.
結構化: 將複雜紙本文件轉換成結構化資訊.
數據化: 將這些資料更有效收集分析與決策判斷.
![]()

")




與文字辨識(OCR)融合:引領文字識別新時代")


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}