

{kind=link}
相信大家都已經很熟悉LLM (Large Language Model, 大語言模型),不過其實現今的大模型已經可以做到多模態(MutilModel)的應用,也就是LLM不在只是可以看懂文字,甚至可以看懂圖片、描述圖片等等,在這個「看」的領域中除了過往的電腦視覺(Computer Vision;CV),因應大模型開始有了VLM(Vision Language Models, 視覺語言模型 ).
簡單地講,就是透過VLM機器可以模擬人的視覺與大腦,看懂圖片內容,例如你可以問他圖片有什麼內容之類,T編來示範給你看吧!
一、先看看其他的大模型可以做些什麼?
- Google Gemini:
當我輸入一張圖片,他的回答:


- ChatGPT:
當我輸入一張圖片,他的回答:

以上你喜歡哪一種回答呢?但至紹可以知道機器會看著圖片內容去回答.
二、這次換成一張表格的圖片我,我希望他幫我做版面分析
- Google Gemini:
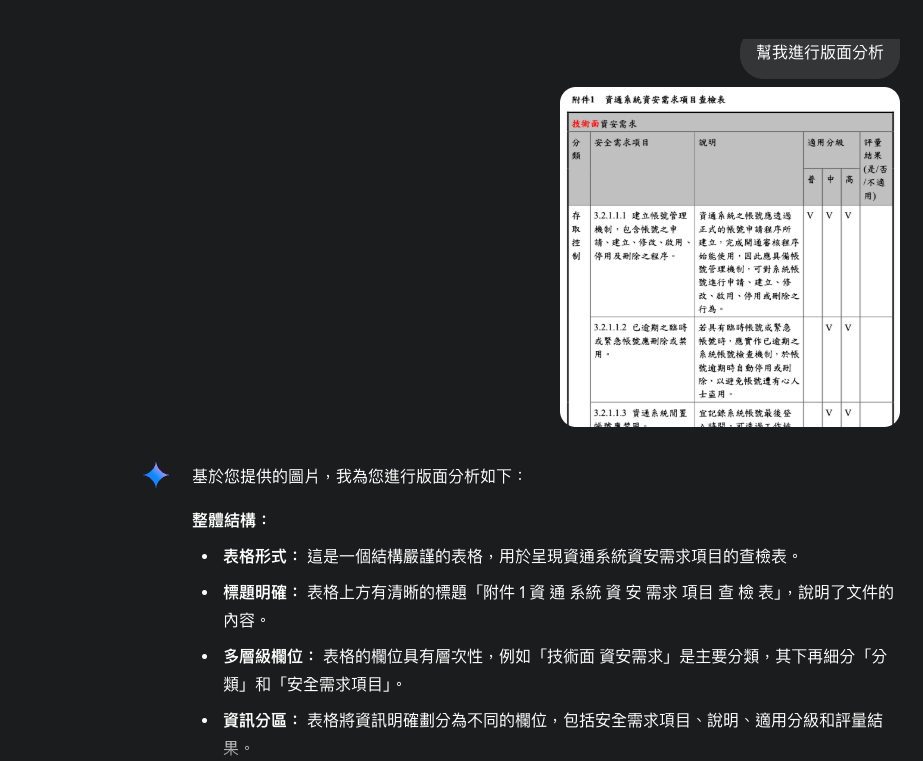
其實這邊也可以看到Gemini還是可以理解這是一張具有表格的圖片,當然因為是Chatbot所以沒有幫我進行版面分析,也有可能是我給的指令不夠,但這邊就讓大家看一下效果.
三、VLM、CV、OCR差異
| 技術 | 核心能力 | 主要處理內容 | 優勢 | 劣勢 |
|---|---|---|---|---|
| VLM(視覺語言模型) | 圖文生成與理解 | 圖片描述、跨模態問答、圖文推理 | 同時處理文字與圖片 | 速度慢,計算量大,耗成本、算力,且訓練數據需要更多 |
| Computer Vision(電腦視覺) | 視覺特徵分析 | 物件識別、圖片分類、場景理解 | 適合做物件偵測(Object Detection)、圖片分類(Image Classification)、人臉偵測..等 | 缺乏理解能力,只通常只能輸出標籤或座標 |
| OCR(光學字元辨識) | 辨識與提取文字 | 文字檢測、文字辨識 | 專注於文字處理,為最底層的核心能力 | 速度快,耗能少,但不具備理解能力 |
本表格參照ChatGPT進行調整.
四、應用場景
| 應用場景 | VLM | Computer Vision | OCR |
|---|---|---|---|
| 掃描或拍照文件(文件、票據、書籍) | 提取文字並理解內容 | 不擅長 | 提取文字 |
| 圖片問答(給圖片後回答問題) | 能基於圖片內容回答 | 不擅長 | 不擅長 |
| 場景描述(自動生成圖片說明) | 可進行跨模態搜索 | 只能輸出標籤(類似分類) | 不擅長 |
| 多模態搜索(輸入文字找圖,輸入圖找文字) | 可進行跨模態搜索 | 只處理圖片 | 只處理文字 |
| 表格理解(辨識票據、財報、圖表) | 能理解表格語意 | 不能處理語意 | 能提取數據 |
本表格參照ChatGPT進行調整.
五、實務應用
由於當作文字抽取或RAG(Retrieval Augmented Generation;檢索增強生成)或是在做一些OCR(Optical Character Recognition;光學字元辨識)相對重要,因為這些表格、圖片、文字、印章、手寫字…等,會影響回答與抽取的應用.
故為什麼要了解一張圖片的佈局就顯得重要,猶如人一樣,透過眼睛看到圖片對應的資訊,再透過大腦來進行分析判斷,而過往的Computer Vision較難做到這點,透過大模型技術,可以補齊這點,讓機器更看得懂圖片理解圖片.
由韜睿的技術,我們可以完整還原出整個圖片的格式佈局,讓應用上更多元.
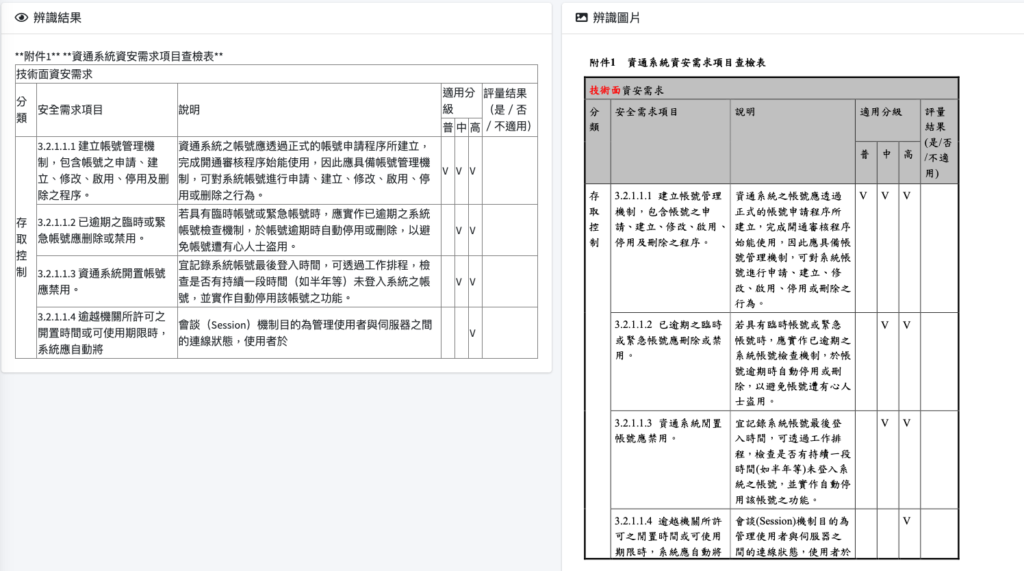
本表格取自國家資通安全研究院.
六、最後T編說
本文章的置頂圖片就是由ChatGPT依據標題產生,你喜歡哪一個呢?

![]()